Link validation pipeline
The Link Checker can be found in the Web section of the action list:
Image loading...
The action scans the provided URL and saves the report as HTML files in the .buddy/ directory of the pipeline filesystem:
Image loading...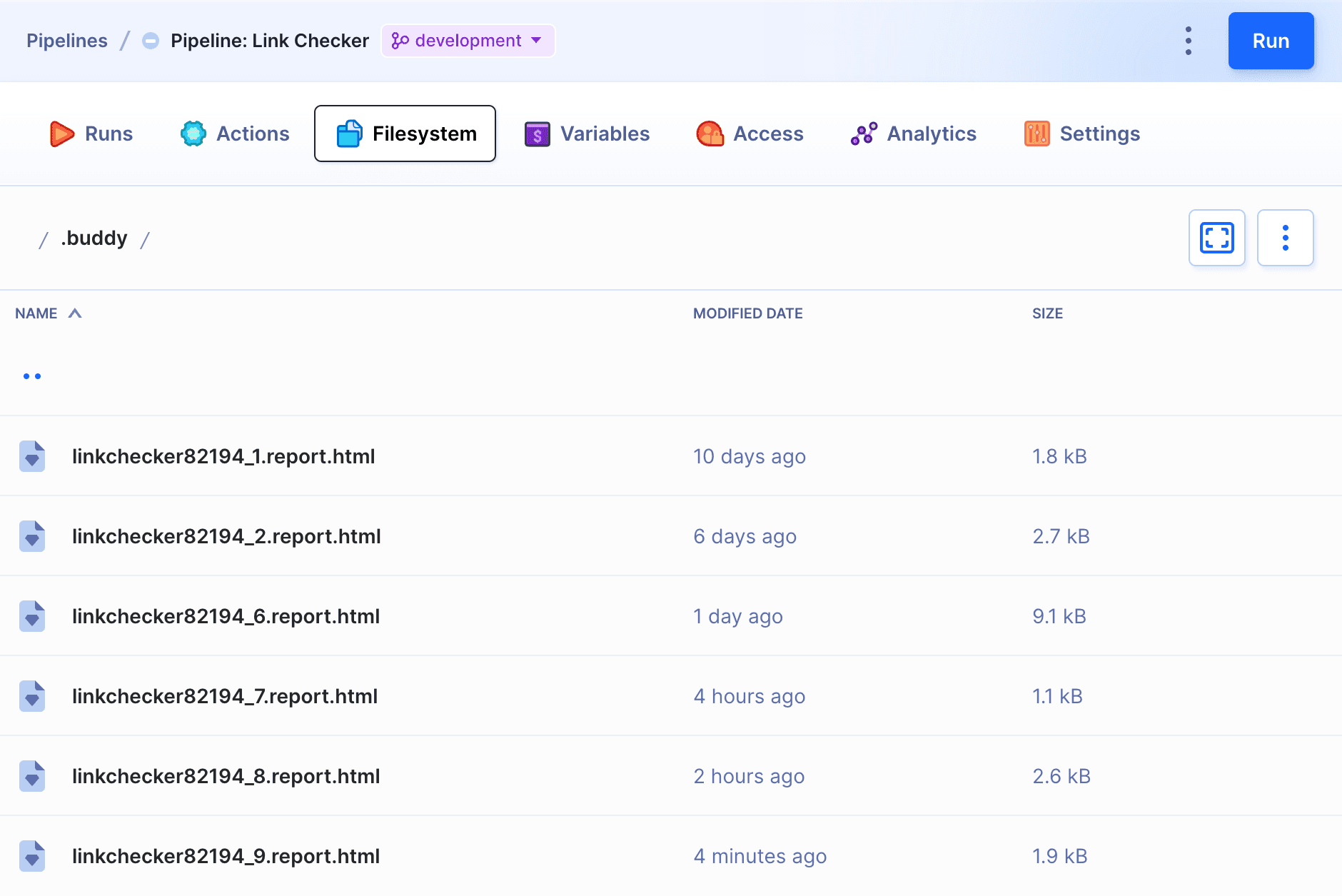
Settings
Authentication
Here you can configure the authentication details to your website.
- HTTP basic authentication – check this option if your website requires username and password.
- HTTP form URL – this option let you define the inputs and values for the username and password. The most common use case are custom admin panels that require authentication.
For example, for these inputs the username and the password are named log and pwd respectively:
html<input type="text" name="log" id="user_login" class="input" value="" size="20" autocapitalize="off" autocomplete="username"> <input type="password" name="pwd" id="user_pass" class="input password-input" value="" size="20" autocomplete="current-password">
Cookies
This section lets you load cookie data (name and value) to the website that you want to check. You can load multiple cookies with the + button.
Settings
The settings let you tweak the behavior of the scanner on the website.
- Threads — the maximum number of threads running on the URL. Default: 10.
- Depth – restricts the recursion level of the scanned URLs on the website.
- Timeout – the amount of time in seconds after which another connection attempt is made. Default: 60.
- User-Agent – the
User-Agentstring sent to the HTTP server. Default values: Buddy, Mozilla/5.0, Mozilla/4.0. Can be customized. - Request per host – the maximum number of requests per second. Default: 10.
- ROBOTS.TXT – turn this option off if you want to validate your website regardless of the ROBOTS.TXT file.
- SSL certificate checking – allows you to verify that your website has an active SSL certificate.
- Additional internal link scheme (REGEX) – allows you to define a REGEX for the URLs to scan, e.g.
SCAN_URL/*. - Follow external links – checks if the links pointing to the external sites are valid.
Ignore URLs (REGEX)
This field lets you define the URLs that should be left out from the scan. Supports REGEX.
Check but don't follow
This option let you define a URL to scan, but will not recurse into URLs that match the entered expression. Support REGEX. For example, entering https://buddy.works/guides/wordpress/.* will ignore all guides in the WordPress category.
Other issues to report when found
This field lets you define a message that will be saved in the report upon finding an issue. Supports REGEX. Example value: (This page has moved|Oracle application error).
Last modified on Mar 4, 2026