What is GraphQL and why Facebook felt the need to build it?
This article is part 1 of the series on Exploring GraphQL. Check out the other articles from the series:
- Part 2: Fundamentals of GraphQL
- Part 3: Building a GraphQL Server using NodeJS and Express
- Part 4: How to implement Pagination and Mutation in GraphQL
- Part 5: Introducing the Apollo GraphQL Platform for implementing the GraphQL Specification
- Part 6: How to Connect MongoDB to a GraphQL Server?
- Part 7: GraphQL Subscriptions - Core Concepts
- Part 8: Implementing GraphQL Subscriptions using PubSub
This tutorial is the first part of the series on Exploring GraphQL. In this part, we will look into the old ways of fetching resources from the server using SOAP and REST and examine the problems with these approaches. We will see why Facebook felt the need for building GraphQL while developing the News Feed section for their IOS application. We will learn how GraphQL solves some of the common problems of the REST architecture. We will then dive deep into the Type System adopted by the GraphQL specification.
The World Wide Web was invented in the early 90s. It was just a pile of HTML pages back then. But the idea that a resource can be transferred over the wires from a server to the client was amazing! There was a lot of enthusiasm among people to try out this new feature. As people started experimenting with the web, they wanted to do a lot more new things than just browsing over the static pages. The animations, scripting, and graphics were improved to have a better experience. Over time, the web revolutionized and is now the largest platform in the history of computing, around 5 billion devices are connected to the web.
Initially, the resource fetching mechanism was implemented using SOAP (Simple Object Access Protocol). It is a messaging protocol specification for exchanging structured data in the form of XML Information Set. It uses HTTP or SMTP as the application layer protocols for transferring the messages across web services. SOAP was doing great and was being used in some of the major projects. However, SOAP did not perform well for low-memory and low-processing-power devices with limited bandwidth. There was a need to build for something better!
Representational State Transfer (REST)
Roy Fielding developed the Representational State Transfer (REST) architecture in the late 90s. REST was designed to increase the efficiency of communication systems.
Representational state transfer (REST) is a programming architectural implementation intended to increase the efficiency of communication in computing systems. It embodies the idea that the best way to share large amounts of data between multiple parties is to make that data available on-demand by sharing references to that data rather than a complete copy of the data itself. Systems which implement REST are called 'RESTful' systems. - Simple WikiPedia
REST aimed to provide a simple and flexible model for data transfer in the form of XML or JSON. It was adopted by the community worldwide. But as the applications became more complex, people started facing problems with the REST architectural style. Let's consider one example to understand this more.
Let's build a Movie Review System. The product manager has stated the requirements for building this application as below
- It will have two views - Movies Listing and Movie details.
- The Movies Listing view will display the name, poster and the average rating of a particular movie. The Movies details view would show the list of reviews for a particular movie.
Image loading...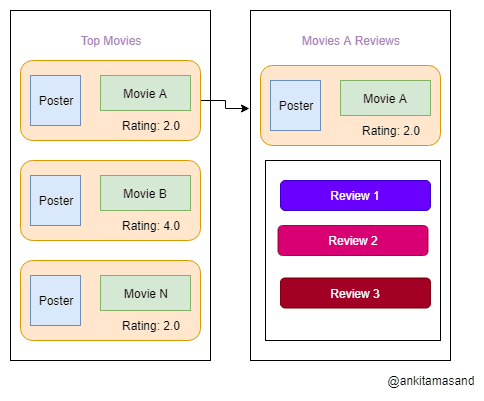
The resources required for building the Movies Listing view are - Movies and Ratings. We will have to make n+1 (n is the number of movies) calls to the server for fetching the list of movies and its corresponding ratings. The movies API /v1/movies should send the response as below:
javascript{ "data": [ { id: 1 name: "Movie A", poster: "/movie-a", rating_id: 101, viewed: "1000", recommended: "200", review_id: 201, cast: { director: 'Blah Blah', // ... }, summary_id: 301 }, { id: 2, name: "Movie B", poster: "/movie-b", rating_id: 102, viewed: "2000", recommended: "400", review_id: 202, cast: { director: 'Blah Blah', // ... }, summary_id: 301 } ] }
The front-end developer uses id, name, poster and rating_id from the above API. He is very stubborn on his coding standards and hence changes the names of some of the keys on front-end to reflect the naming convention being used in Javascript. He makes rating_id as ratingId. He then traverses the entire list and makes API calls to fetch ratings for each of these movies as:
javascript/v1/movies/ratings/{rating_id}
And gets the response as
javascript{ data: [ { rating_id: 101, rating: 2, //... some more garbage data as always } ] }
He simply ignores the rest of the data and displays the value of rating.
Please note: We have to make separate calls for fetching movies and ratings as these are two different resources and should ideally be in different models in a Database Schema. The developer can hack around this problem by building a custom endpoint that would return the result in one API call. However, this approach is not scalable and is not the ideal way to solve a problem. If a requirement changes, we will have to modify the implementation of the custom endpoint to handle various use-cases.
Can we reduce the number of API calls?
Certainly! We can reduce the number of API calls from n+1 to 2. We can batch the ratings API to get the list of ratings for all the movies in one go!
Let's see how this can be done:
javascript// Endpoint movies/ratings // Request Parameters { ratingIds: [101, 102, 103] }
The response of the above API would be
javascript{ data: [ { rating_id: 101, rating: 2, //... some more garbage data as always }, { rating_id: 101, rating: 2, //... some more garbage data as always } ] }
The reviews page could be implemented in a similar way. It shows the details of the movie and its reviews. We make the following API calls to implement this functionality:
- Fetching the details of a movie
/v1/movies/{movieId} - Getting its reviews
/v1/movie/reviews/{movieId} - Getting the number of likes on each review -
/v1/movie/reviews/{reviewId}
While we were about to ship our product, the product manager came in with another requirement of displaying the number of users who have rated the movie. While the back-end guy was sending a lot more information than needed in the ratings API, he did not have anything in store for the number of users. So changes were required on the back-end as well as front-end to incorporate this change.
Clearly, there are some problems while fetching data using REST. These problems are listed below:
Multiple Endpoints
REST was designed as a resource fetching mechanism. So different resources are fetched using different endpoints. In our example above, we have different endpoints for movies, ratings and reviews. The front-end developers literally maintain a list of these endpoints in a separate file to make sure nobody tampers this file in any way.
Under-Fetching
The design style of REST deals with resources. In general use-cases, a typical functionality is implemented using at least two to three resources. In our case, we used Movies and Ratings resources to implement a simple movie listing page. We have to make two round trips to the server for fetching data of movies and ratings. The number of API calls is dependent on the number of resources being used for developing the user interface. In more complex scenarios, the number of round trips can increase up to 5 or 6 for fetching data for the initial load.
Over-Fetching
As we saw earlier in the /v1/movies API, some of the fields in the API were not used in the application. A lot of unnecessary data is being sent across the wires and this impacts the performance of an application. There is no systematic way of telling back-end developers what all fields are required on the front-end. The API simply returns all of the fields that are defined in the resource model.
Versioning
The first phase of our Movies Reviews system uses v1 in the API calls. The versioning of APIs is done to avoid any breaking changes in the applications. We will have to use v2 for the second phase of our application to support more complex functionalities. If not for versioning, changes in the initial APIs could tear down the application. Models and Views are tightly coupled.
Let's say the android native application for movies reviews system uses v1 version for API calls. The developers made some breaking changes in the API and versioned them as v2. The app users who did not update their application would still be using the version v1 for interacting with the back-end. Versioning helps in supporting the older instances of an application.
If we want users to use our new features in the native application, we will have to force them to update the application from play store. This is not a good user experience.
Syncing between back-ends and front-ends
This approach hinders the rapid iterative development on front-end. If any changes are to be made on the view, it is likely the case that those changes are to be handled on the back-end as well. This kills productivity and increases the dependency on developers.
Why Facebook built GraphQL
You might have not realized that these problems exist with the REST way of fetching resources. But companies like Facebook, Twitter, GitHub and many more started facing issues with the REST implementation as the complexity of their application increased to many folds.
The developers at Facebook were finding it difficult to implement the News Feed section for their IOS application. During their development phase, they experienced a lot of bugs because there was no convention regarding the exchange of data between the front-ends and the back-ends. The shape of the data assumed by the front-end was different than the one being sent by the back-end APIs. There was a need to build something better!
Facebook solved this problem by building GraphQL. GraphQL is a static strong-typed query language that let clients declaratively specify their data requirements. The clients specify the shape of the data that they need and the server responds back with the exact same data as the response. The client is in control of the view! This leads to fewer or no bugs. Let's write our first hello world query in GraphQL:
graphql{ me { name } }
This looks a lot like the JSON structure. The client asks the server the name of the currently logged in user and the server would send in the JSON response as below:
graphql{ "me": { "name": "Tim Berners Lee" } }
The query sent by the client specifies the shape of the data and the server responds back with the exact same shape.
This solves our problem of under-fetching and over-fetching. It is not the head-ache of client anymore to collect data from different end-points. The client just specifies the shape of the data it needs and then it is the job of the server to get the work done. That's exactly how we solved one more problem of handling multiple endpoints with the REST style of doing things.
There is only one endpoint in GraphQL and the query is passed as a string to the server. Let's check out one more query to understand better:
graphql{ me { name, posts { title, body } } }
The above query asks the server to send in the name of the currently logged in user, posts along with their title and body content. The server sends back the response as:
graphql{ me { name: "The Free Radical", posts: [ { title: "Progressive Web Applications", body: "...." }, { title: "A Beginners guide to getting started with React", body: "..." } ] } }
The client does not make any assumptions here. It clearly knows the shape of the response. Notice the type of posts as an array of objects and each of these objects contain the title and body as specified by the client. Let's try to implement the same use-case using REST and understand the subtle differences between the two of them:
json// Fetching User details /v1/user Fetching posts /v1/posts
We will have to query two different endpoints to get the resources accordingly. Also, the shape of the response is not in sync with that of the client. The server might send a few extra fields and could send some of the fields with different names of different data types. There is no contract between the client and the server.
GraphQL Type System
GraphQL uses a type system to validate queries sent by the client. The entities are represented in the form of a Schema. The client can request only those fields that are defined in this schema. The type system describes the capabilities of the server. Let's consider the hello world query again to understand more:
graphql{ me { name } }
me and name are called fields. The content inside { } is called as a selection set. This is the structure of the query on the client-side. However, before executing this query, it should be validated on the server-side to check if such data exists. The validation of the query will be done against the User type. Let's see the definition of the User type:
javascripttype User { id: String! name: String! }
The above client-side query is of type User. As we can see from its schema, it has two fields - id and name of type String. The exclamation mark at the end of the field definition signifies that it is a non-nullable field. The server will return some value other than null for this field.
If the client requests something like -
javascript{ me { name location } }
The server would throw an error before executing the query as location field is not defined on the User schema.
Scalar Types in GraphQL
The name field in the above query is at the leaf level. It would resolve to concrete data at run-time. The fields that yield some data at run-time and can longer be divided into sub-fields are called Scalar Types. GraphQL supports the following scalar types:
Int: A signed 32-bit integerFloat: A signed double-precision floating-point valueString: A UTF-8 character sequenceBoolean:trueorfalseID: It is used as a unique identifier
Enumeration Type
We can also define enums in the GraphQL schema as:
graphqlenum postCategory { TUTORIAL PRODUCT PROMOTIONAL }
The enum postCategory restricts the value of postCategory field to be one among TUTORIAL, PRODUCT and PROMOTIONAL. The GraphQL engine would throw an error if the postCategory field holds any other value than the ones listed above.
Object Types
Object Types, scalars, and enums and the only kinds of types that can be defined in the GraphQL Schema. We have already learned about Scalars and enums. The Object Types are the basic components of a GraphQL schema. They represent the shape of the schema that you can fetch from the server. For example, let's consider the User type:
graphqltype User { id: String! name: String! }
The User type defines the fields that can be queried for a user. It is called as an Object Type.
Lists in GraphQL Schema
We can define the type of a field as List by using [] as:
graphqltype Post { id: String! title: String! body: String! } type User { id: String! name: String! posts: [Post] }
Notice the type of posts field in the User type. It is an array of type Post. We can add type modifiers to the above User type declaration as:
graphqltype User { id: String! name: String! posts: [Post]! }
The exclamation mark at the end of the posts field suggests that the value of posts cannot be null. It will have some definite value. To indicate that the list can be empty but the values inside it cannot be empty, we will have to define the posts field as below:
graphqltype User { id: String! name: String! posts: [Post!] }
Exploring GraphiQL
The GraphQL team has built an amazing user-interface GraphiQL to play around with GraphQL queries. Let's see some of the Star Wars queries in action:
graphql{ allPeople { people { name, birthYear, gender, height } } }
When you execute the above query in GraphiQL, it will return the response in the same format as expected. This is the response returned for the above query:
graphql{ "data": { "allPeople": { "people": [ { "name": "Luke Skywalker", "birthYear": "19BBY", "gender": "male", "height": 172 }, { "name": "C-3PO", "birthYear": "112BBY", "gender": "n/a", "height": 167 }, { "name": "R2-D2", "birthYear": "33BBY", "gender": "n/a", "height": 96 } ] } } }
people is an array of objects having the same shape as required by the client.
On the right-hand side of the GraphiQL, you will find a link for the documentation. GraphQL also helps with the documentation of Type Systems. We will learn more about it in the later articles of the series. Click on root to see all the fields defined on it. root is an object type. Expand the allPeople field. Notice its type as PeopleConnection. Let's check the fields defined on the type PeopleConnection. The people field is of type list of Person type. The Person type has a number of fields including id, name, birthYear, etc. We are only using some of these fields in our view and GraphQL sends back only those fields in the response. Cool Stuff!
Let's do something interesting!
Image loading...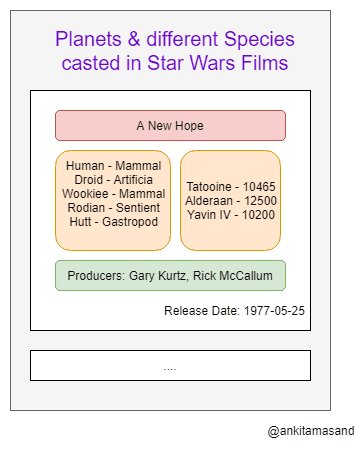
Here we want a list of films. Each of these films have some connections with different types of species and planets. The use-case is to list down the films' title, releaseDate, producers, speciesConnection and planetsConnection. The speciesConnection is of type list with fields as name and classification. The field speciesConnection is also of type list with fields as name and diameter.
js{ allFilms { films { title, releaseDate, producers, speciesConnection { species { name, classification } }, planetConnection { planets { name, diameter } } } } }
Try out the above query in GraphiQL. Here's the shape of the response for the first film:
graphql{ "data": { "allFilms": { "films": [ { "title": "A New Hope", "releaseDate": "1977-05-25", "producers": [ "Gary Kurtz", "Rick McCallum" ], "speciesConnection": { "species": [ { "name": "Human", "classification": "mammal" }, { "name": "Droid", "classification": "artificial" }, { "name": "Wookiee", "classification": "mammal" }, { "name": "Rodian", "classification": "sentient" }, { "name": "Hutt", "classification": "gastropod" } ] }, "planetConnection": { "planets": [ { "name": "Tatooine", "diameter": 10465 }, { "name": "Alderaan", "diameter": 12500 }, { "name": "Yavin IV", "diameter": 10200 } ] } } ] } } }
While REST would have taken multiple round trips to fetch the above information, GraphQL does that in one single round trip.
Conclusion
In this tutorial, we built up the foundations of GraphQL. Let's recap all that we have learned so far
- There are some issues with the REST Architecture style such as Multiple endpoints, Over-fetching, and Under-fetching of resources. There is no efficient way of handling various versions of native applications.
- Facebook experiences these problems with REST and hence built the GraphQL. GraphQL is a declarative way of specifying the data requirements on the client-side. It can be operated on a single end-point. It is more structured than REST.
- We can fetch multiple resources in a single endpoint. This reduces the time wasted in multiple round-trips from the browser. With GraphQL, the client specifies the data it needs in the form of a query. The server sends back the response in the exact same shape.
- GraphQL has a schema definition language for defining the types on a query. This makes it easy to develop applications without making assumptions on the type of fields.
- The Object types, scalar types, and enums are the only kinds of types that can be defined in the GraphQL schema.
In the next article, we will learn more interesting things as listed below:
- How to pass arguments in a query
- How to define Alias and Fragments
- How to reuse the GraphQL types by using interfaces
- What are Mutations and Subscriptions in GraphQL