GraphQL Subscriptions - Core Concepts
This article is part 7 of the series on Exploring GraphQL. Check out the other articles:
- Part 1: What is GraphQL and why Facebook felt the need to build it?
- Part 2: Fundamentals of GraphQL
- Part 3: Building a GraphQL Server using NodeJS and Express
- Part 4: How to implement Pagination and Mutation in GraphQL
- Part 5: Introducing the Apollo GraphQL Platform for implementing the GraphQL Specification
- Part 6: How to Connect MongoDB to a GraphQL Server?
- Part 8: Implementing GraphQL Subscriptions using PubSub
GraphQL has taken over REST! The GraphQL way of doing things solves some of the major problems like OverFetching, UnderFetching, Multiple end-points, Versioning, etc. The GraphQL specification contains a strong type system, query language, rules for validating, parsing and executing operations. The types in GraphQL are defined using the Schema Definition Language (SDL). We've learned about the two important GraphQL operations -- Query and Mutations in this article. The GraphQL enables the client to have control over the data. The client specifies the fields and the structure of the expected response and the server sends back the response in the exact same shape to the client. This is the power of GraphQL!
The query and mutation operations follow a request-response cycle. The client sends a query to the server. The GraphQL layer parses the query and constructs an Abstract Syntax Tree and then validates the fields in the query. The query is then executed and the response is sent back to the client. The process can be illustrated as:
Image loading...
Let's say the client sends a query to the server to fetch 10 most recent tweets in JavaScript. The server processes the request and sends back the result. The client displays the result on the front-end.
And someone just tweeted about JavaScript!
The client will not get this tweet until it re-sends the fetch request to the server. The problem is clear here! The request-response cycle is stateless in nature and there is no continuous connection between the server and the client. This would require an un-ending connection between the server and the client to get the recent updates (read real-time data) happening on the server-side.
The GraphQL has solved the traditional query/mutation operations in the most efficient manner but can it solve the real-time data fetching issue? Let's find out in this article.
In this article, we're going to understand how GraphQL solves this problem of fetching real-time data using GraphQL Subscriptions. We're going to break down the complex concepts involved in GraphQL Subscriptions and learn them bit by bit. Let's start off with an intuitive approach of fetching real-time data:
Table Of Contents
- The Novice Approach to Fetching Real-time Data
- Polling
- Push-based Approach
- Event-based Push Subscriptions
- Real World Use-case - How Facebook uses GraphQL Subscriptions in Production
- How GraphQL Subscriptions work under the hood?
The Novice Approach to Fetching Real-time Data
We can hit the tweet fetching API again to get the updated data from the server. New tweets might get added in seconds so we'll have to keep calling this API in intervals of a few seconds to get the updated response. There will be some API calls, where we'll get the same response as the previous one because there were no newer tweets. This is clearly an inefficient solution and a waste of precious resources (read round-trips to the server).
However, let's assume there are newer tweets available, the tweet-fetch API will get these newer tweets. These tweets will now occupy the viewport of the user. The user has no idea why the tweet he was reading pateiently has gone out of his viewport. This doesn't look good from the user's perspective.
We can, however, use this approach while fetching real-time stock prices. The moving graph of the stock prices makes sense!
Image loading...
This can be a good solution when data changes too frequently and latency should be as minimal as possible.
Polling
We can optimize the above solution for fetching tweets as:
The client periodically issues a request to check on the state of the data it cares about.
The client polls on the server only to check if the state of the data is changed (or new tweets are available). This is a simple solution when updates happen over some fixed interval. However, if updates are infrequent, polling may not be useful. Also, if updates are frequent and data changes too fast like in stock-based use-case, polling may introduce additional latency.
Push-based Approach
Another solution to fetching real-time updates is letting the server tell us if anything is changed. This is a push-based technique, where the server tells the client about the updated state of the data that it cares about.
Twitter employs a clean technique to solve this problem. Here's a screenshot of Twitter Web:
Image loading...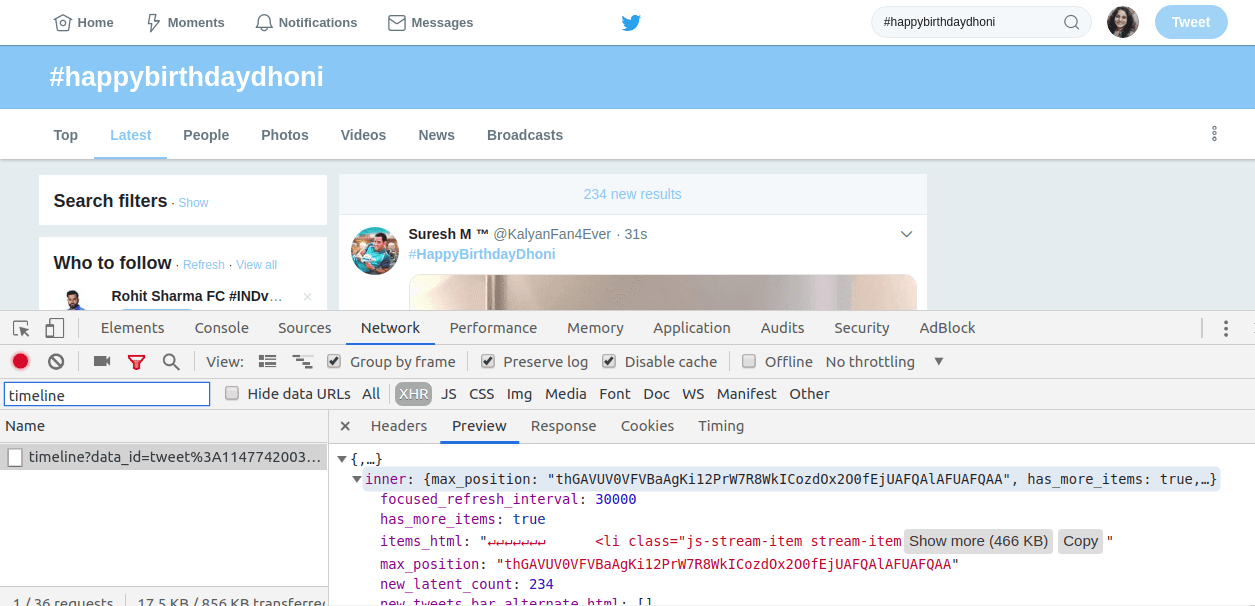
The bar that shows 234 new results is an amazing user experience to tell clients that new tweets are now available for your search result (which in my case is #happybirthdaydhoni).
Check out the API response in the Network tab in DevTools below in the screenshot. The timeline API has a new_latent_count field in the response. Note the value of new_latent_count as 234, which is mentioned in the top bar. These new tweets would be fetched only when the user clicks on the bar.
The server pushes data to the client only when new tweets are available!
Push technology, or server push, is a style of Internet-based communication where the request for a given transaction is initiated by the publisher or central server. It is contrasted with pull/get, where the request for the transmission of information is initiated by the receiver or client. - Wikipedia
Event-based Push Subscriptions
The client tells the server about the events it is interested in. Whenever those events trigger, the server notifies the client. In our case, the event is New tweet for a ${category}. Please note: category is a variable here; it is happybirthdaydhoni in our case. Whenever there is a new tweet available for the respective category, the server should send an alert to the client. This is Event-based Push Subscriptions.
The client is subscribed to an event and is interested in getting further updates when the event happens.
Let's see how Event-based subscription approach is related to GraphQL Subscriptions.
Overview of the RFC on GraphQL Subscriptions
Image loading...
If you're wondering what RFC is-- here's what I found on Wikipedia:
Request for Comments (RFC), in information and communications technology, is a type of text document from the technology community. An RFC document may come from many bodies including from the Internet Engineering Task Force (IETF), the Internet Research Task Force (IRTF), the Internet Architecture Board (IAB), or from independent authors. The RFC system is supported by the Internet Society (ISOC).
An RFC is authored by engineers and computer scientists in the form of a memorandum describing methods, behaviors, research, or innovations applicable to the working of the Internet and Internet-connected systems. It is submitted either for peer review or to convey new concepts, information, or occasionally engineering humor.
The possible API solutions as mentioned in the RFC on GraphQL Subscriptions are classified as Polling, Event-based Subscriptions, and Live Queries. We've already seen Polling and Event-based Subscriptions. Here's an excerpt on Live Queries from the same RFC link:
The client issues a standard query. Whenever the answer to the query changes, the server pushes the new data to the client. The key difference between Live Queries and Event-based Subscriptions is that Live Queries do not depend on the notion of events. The data itself is live and includes mechanisms to communicate changes. Note that many event-based use cases can be modeled as live queries and vice versa. Live Queries require reactive data layers, polling, or a combination of the two.
We'll learn more about the Live Queries in our later articles. But let's now focus on the event-based approach that GraphQL uses for subscriptions.
We're now clear on what a subscription is and how GraphQL uses event-based Subscriptions to send updated information to the client about the event that it is interested in. Let's dig deeper and understand more!
Real World Use-case - How Facebook uses GraphQL Subscriptions in Production
One of the places where Facebook uses GraphQL Subscriptions is in its NewsFeed.
Let's say you're scrolling your newsfeed on your facebook and now there are 3 stories in your viewport. Have you noticed that the likes and comments on the stories in your viewport get updated dynamically (without you doing anything)?
Let's say you're currently viewing a post from Mark Zuckerberg (or of someone who has many followers). The likes count on the post keeps increasing in a matter of milliseconds.
How is Facebook doing that?
Hitting the likes and comments API again and again? Nah! It subscribes to the likes and comments event for the particular stories in your viewport. And once you start scrolling, it unsubscribes you from the previous stories and you get subscribed to the new ones currently in your viewport.
When you get subscribed to a story, an un-ending connection gets built between the client and the server. The server notifies the client whenever the events (likes and comments) are updated on the server for these particular stories. Isn't this an interesting use-case? Let's dig deep and find out how GraphQL subscriptions actually work under the hood.
How GraphQL Subscriptions work under the hood?
We saw earlier how queries and mutation operations get parsed, validated and executed inside the GraphQL layer. The subscription is also one of the operations that are handled by the underlying GraphQL engine. Here, the Execute block gets replaced by the Subscribe block as:
Image loading...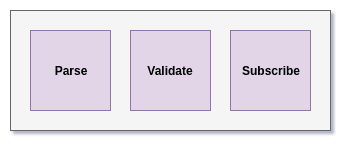
Let's break down this subscribe block and see how it works:
Here's the definition of Subscriptions from the GraphQL specs:
If the operation is a subscription, the result is an event stream called the Response Stream where each event in the event stream is the result of executing the operation for each new event on an underlying Source Stream.
Event Streams
Event Stream, Response Stream, Source Stream? Eh? Don't worry if you didn't understand any of these terms. We're going to get them right away!
Let's first understand what is an Event Stream:
Event stream builds up a continued connection between the source and the receiver to send events over time.
The source sends the relevant data packets to the receiver as and when the event happens at the source end. This can be illustrated as:
Image loading...
If this makes sense then understanding Response Stream and Source Stream is no big deal!
The result of the subscription operation is this event stream that establishes an un-ending connection with the client and sends events on this stream. Also, these events on the response stream are happening because some operation was executed on another stream (source stream).
Let's apply this to our likes count use-case on Facebook. If somebody likes a post that is currently in your viewport, it means some event happened on the source stream. This event will be communicated to you using the response stream that you are subscribed to.
Please note: this stream will close either when there is an error of the source or client explicitly sends a cancellation signal.
Cool, got it! Event Stream is a continuous flowing of events from the source to the client. But how do we implement this?
Implementing Event Streams
We already implement streams in NodeJs as:
javascriptconst stream = createStream() .on('data', message => console.log(data)) .on('error', error => console.error(error)) .on('end', process.exit(1))
Notice the callbacks for data, error and end events. We can use stream.destroy() to send the cancellation signal.
We can also implement streams using RxJs Observables as:
javascriptconst stream = new Observable(subscriber => { // send events }) stream.subscribe( data => { console.log(data) }, error => { console.error(error) }, complete => { console.log('complete') } )
We'll have to include rxjs as a dependency to implement streams using observables.
If you don't want to include any dependency in your project, you can use async iterators. The async iterators are already proposed to be added in the core JavaScript environment but you can also use them now using the Babel transpiler.
The streams can be implemented using async iterators as:
javascriptconst stream = createAsyncIterator() // createAsyncIterator function can be defined using async keyword in a generator function for await (let message of stream) { console.log(message) }
for-of is a great addition in JavaScript for iterating asynchronous pieces. You can read more about it here
This is it! Now we know how to create streams! Let's head over to the next part and see how can we include these streams in our Subscribe block:
Digging deep into the Subscribe block
The subscribe block contains a createSource function that takes in a valid query and returns an event stream.
Whenever there are any updates and a data packet is to be sent to the client, this data packet travels over this stream and is executed by the Execute block.
There is also a mapper function that takes in the source event stream and maps it to the response from the execute block and returns the mapped response stream to the client. I hope event streams, source streams, response streams now make sense!
Let's see how these pieces would look inside the subscribe block:
Image loading...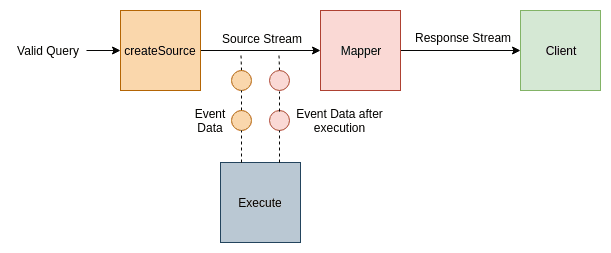
We would be implementing GraphQL Subscriptions using pubsub in the next article. The create source block in the pubsub implementation would be the pubsub topic. This will become clearer once we start writing the code.
We've connected these components and everything looks great! But there is one issue here -- how do we make sure that there is a persistent connection between the client and the server? How do we handle the transport?
We can use WebSockets, MQTT or post to a webhook. We'll be using subscriptions-transport-ws for our transport layer. We'll get to the details of this module in our next article. Until then, have fun learning GraphQL.
Conclusion
In this article, we learned a lot of things related to Subscriptions and some of the ways to implement them. We saw GraphQL uses Event-based subscription model to communicate real-time data to the client. We then learned about the internals of the subscribe block. In the next article, we'll implement GraphQL Subscriptions using pubsub.
Next in series: Implementing GraphQL Subscriptions using PubSub