3 Tricks to Make Your Python Projects More Sophisticated
Image loading...
Image source: Reddit
{kind=link}
Data engineering is a fascinating field. We are dealing with a variety of tools, databases, data sources in different forms and shapes, and ETL jobs processing vast amounts of data every day. Due to the diversity of tasks and technologies, it pays off to know some useful tricks to make you more productive with respect to data processing and code deployments. In this article, we’ll look at three hacks that will make your Python projects more efficient.
1. Using a temporary directory
When reading data from flat files, many data engineers use libraries such as pathlib and shutil to create directories and remove them at the end of the script to ensure that the data pipeline remains idempotent, i.e., that a subsequent run can be executed without any undesirable side effects.
What are the typical use cases when you may need a temporary directory? If your data resides in S3 or on some remote servers, and you have to first download data for further processing and perhaps eventually load the transformed and polished data to a data warehouse or some other database. A temporary directory is also useful if you need to obtain data from an external API, which returns data as JSON. Sometimes, you may also want to cache data to some temporary location. All those use cases can benefit from a temporary directory.
Here is an example of how it could look like by using pathlib and shutil:
Image loading...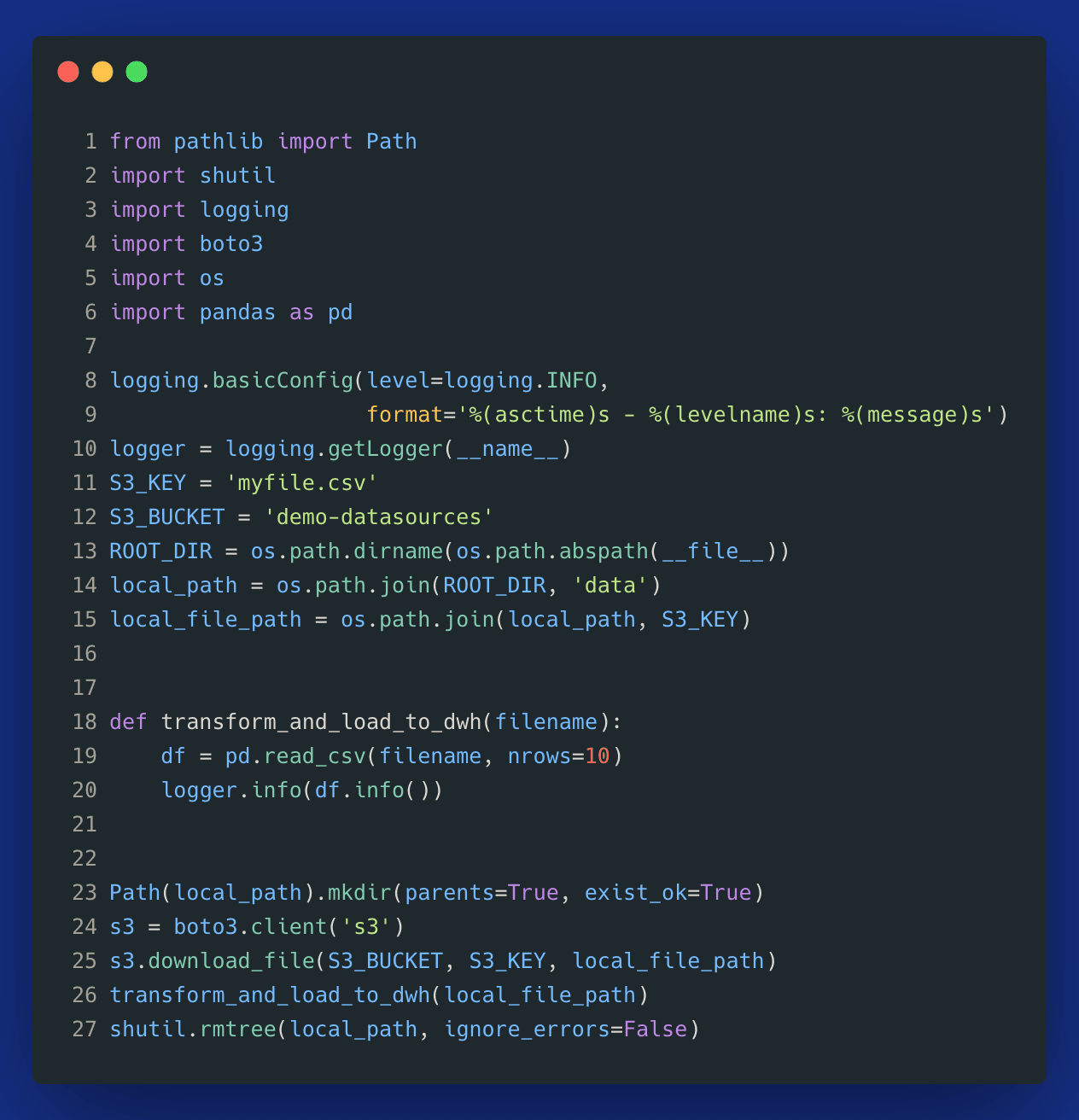
On line 23, we create a directory data under our root project directory. In the end, on line 27, we remove this directory just before our script ends to ensure that we don't accidentally ingest the same data more than once (idempotency issue).
The above pattern works fine. However, a more sophisticated and robust approach would be to leverage a temporary directory. Python makes it easy due to a built-in package tempfile. Here is the same example using the tempdir pattern:
Image loading...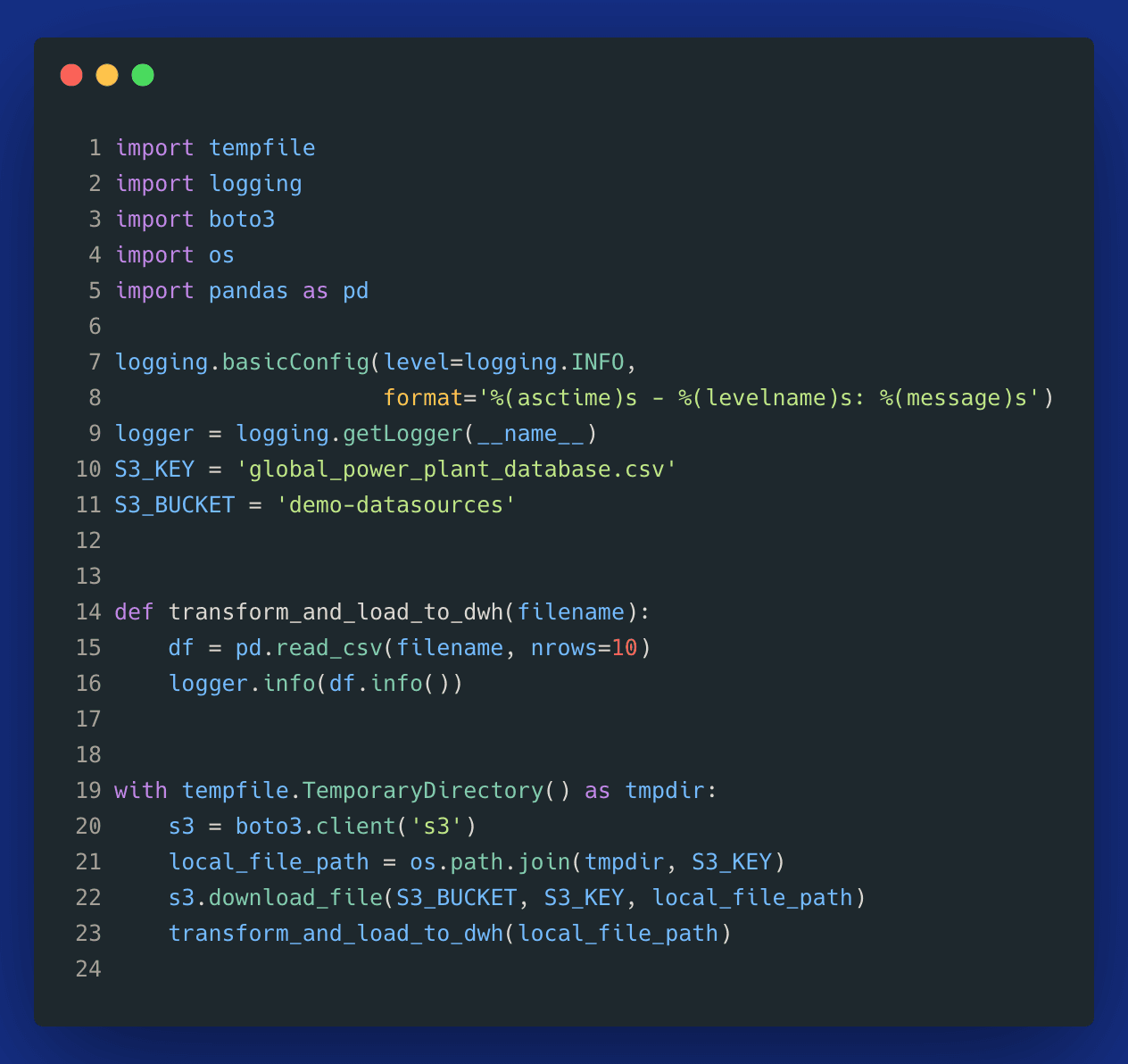
On line 19, you can see how easy it is to create a tempdir. The entire script becomes much simpler and more robust since we can ensure that any temporary files will be removed:
“On completion of the context or destruction of the file object, the temporary file will be removed from the filesystem.” — Python documentation
This way, we make our code more readable and less verbose, and tempfile takes care of cleaning up the resources to ensure idempotency.
2. Using itertuples rather than iterrows in Pandas
If you need to iterate over a Pandas dictionary, you may use the popular method .iterrows(). However, if you don’t need access to the dataframe’s index, you may prefer a potentially more sophisticated method called .itertuples(). Why is it more sophisticated? For one, it’s more readable. Additionally, it’s faster since it operates on tuples rather than on Pandas series and doesn’t have to perform any expensive type checks. This article explains it in more detail.
Here is an example showing how we can iterate over a dataframe with .iterrows() to find all countries and capitals that contain the letters 'ar':
Image loading...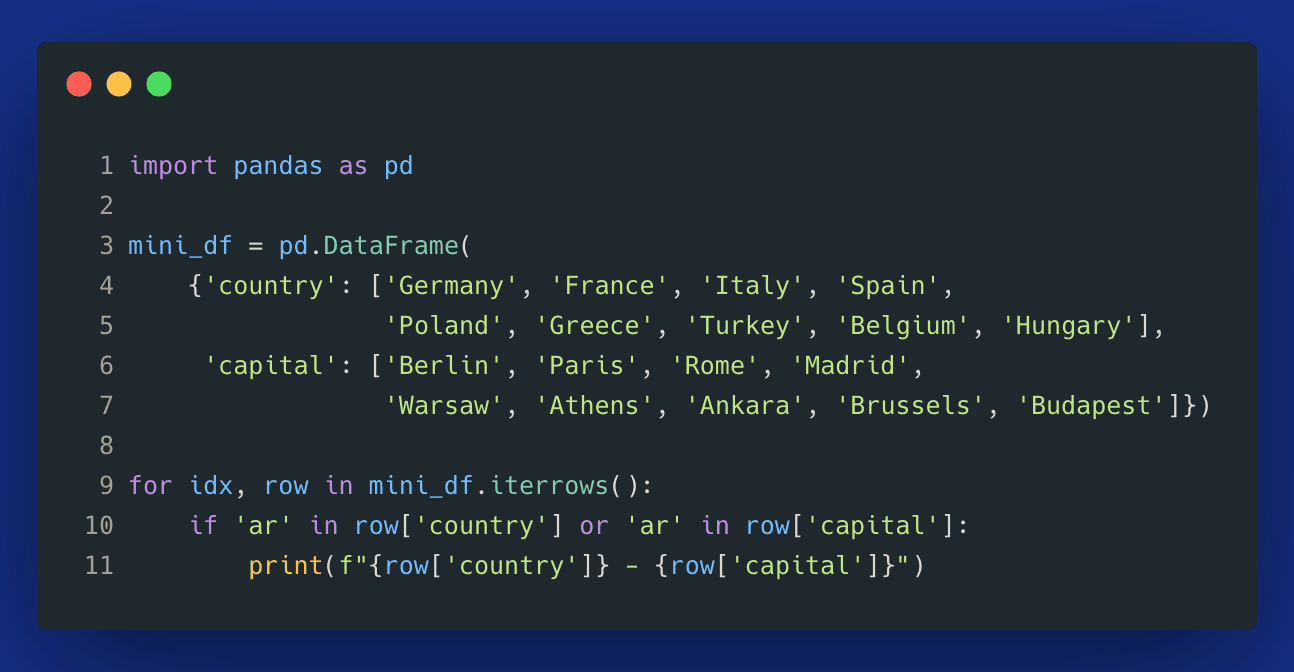
The same solution using .itertuples():
Image loading...
Note that with tuples, you can no longer use the bracket notation. This means that if you have some column names that contain spaces, this method will only work after renaming columns. But it’s worth considering given that in many scenarios, simply replacing .iterrows() by .itertuples() can speed up your code execution by orders of magnitude.
This method is also handy to easily create a dictionary from two Pandas series, which in this example gives us a mapping of countries to the corresponding capital cities:
Image loading...
3. Building a CI/CD pipeline for your Python code
Once you’ve built a great Python project, you may need to deploy it to production. Doing it manually is highly inefficient and often discouraged in the world of DevOps and GitOps.
There are many tools that allow you to create a CI/CD pipeline, such as Github actions or Bitbucket pipelines. However, they require prior DevOps knowledge on how to write declarative YAML files with shell commands to execute all steps required for an automated build in a reliable manner. By far, the easiest tool to accomplish a continuous deployment is Buddy. With a few clicks in your browser, you can build highly sophisticated CI/CD pipelines with no DevOps involved. And there is a free tier for students and freelance developers.
To see how it works, let’s deploy a simple ETL script with Docker. Feel free to clone the following repository and use it as a template: https://github.com/anna-anisienia/simple-etl.
Our goal is that every push to a master branch (or now, potentially a “main” branch) triggers an automatic build that will push a new version of our ETL container image to a Docker registry of our choice. To make it simple, we’ll use Docker hub.
Image loading...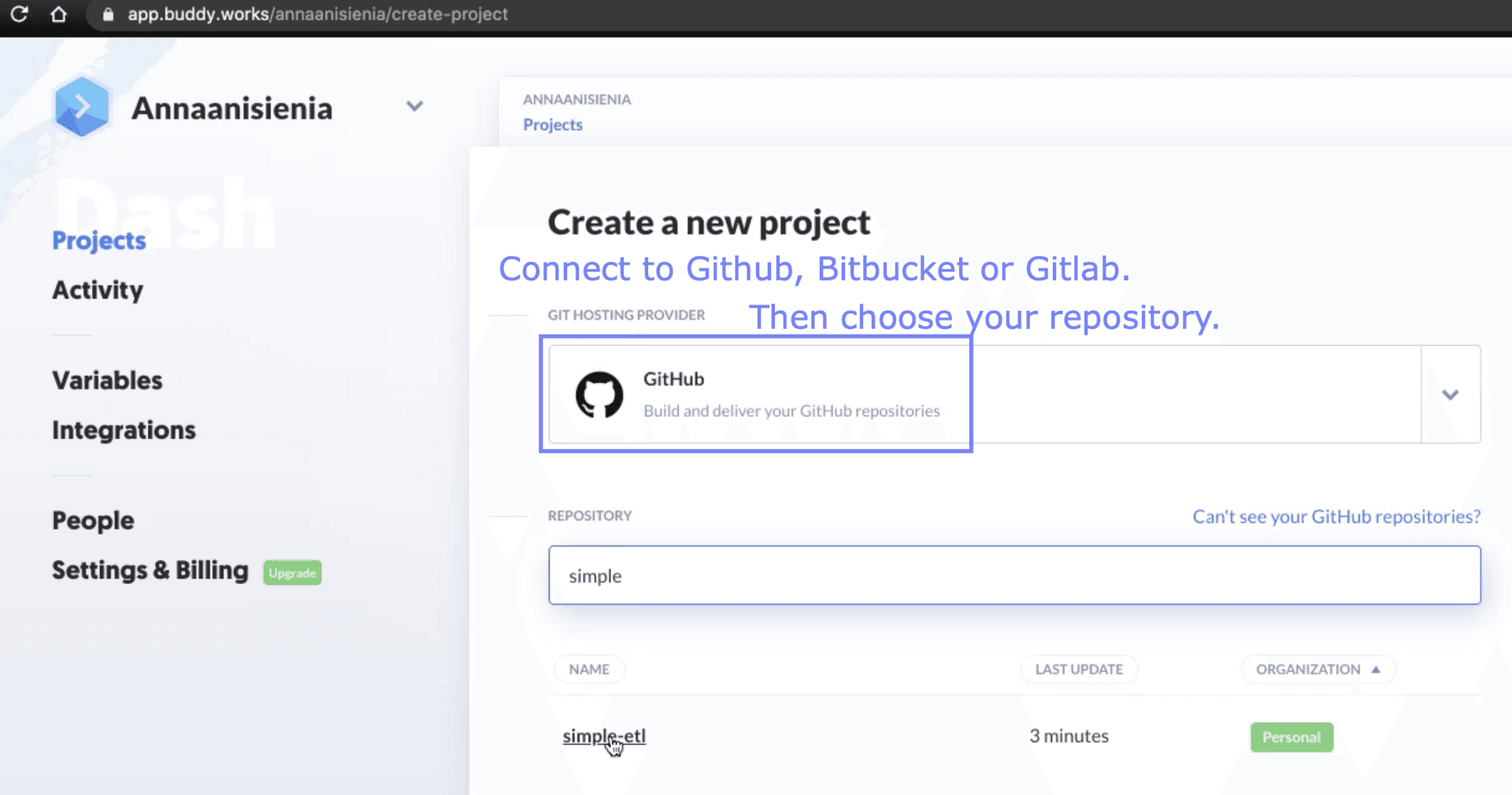
After signing up and connecting our repository, we can select when the build should be triggered. Here, I chose after every push to a master branch.
Image loading...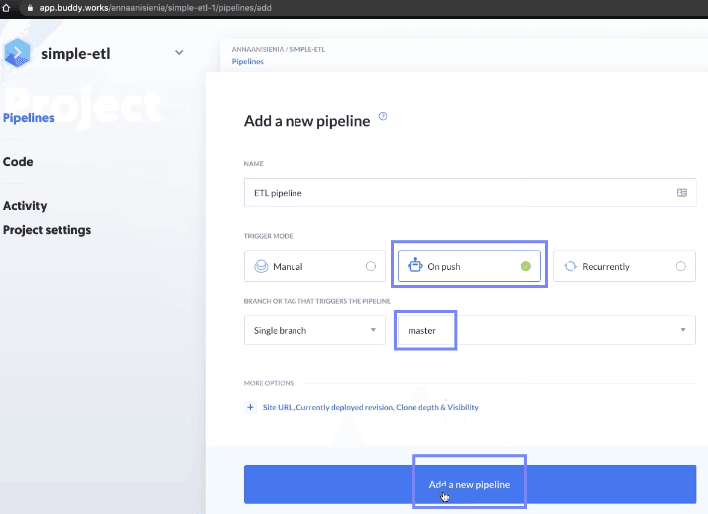
After adding a new pipeline, we can choose from a variety of available actions to configure automated continuous deployments. In the screencast below, you can see how to configure deploying this ETL example to a Docker hub image:
If you followed the steps from the demo, you could test the functionality by making a small change to the ETL script and pushing your committed changes to Git. Then, sit back and enjoy the beauty of automation — your deployment is taken care of, and you don’t need to do anything manually. You can also clone the existing pipeline and perform similar steps to automate builds for your development environment, perhaps by making use of dev branch.
Overall, DevOps and GitOps have become an important discipline in software engineering. But I’m not sure whether data scientists and data analysts doing Python projects need to necessarily know Kubernetes and dedicated DevOps/GitOps tools because it’s really not something they were hired to do. There is an interesting discussion about that in this LinkedIn thread by Demetrios Brinkmann.
By leveraging platforms such as Buddy, you can follow the best practices without spending your time on writing CI/CD manifest files. If you want to strictly follow the GitOps principles and have everything versioned-controlled in your Git repository, you can download your CI/CD pipeline as a declarative YAML file:
Image loading...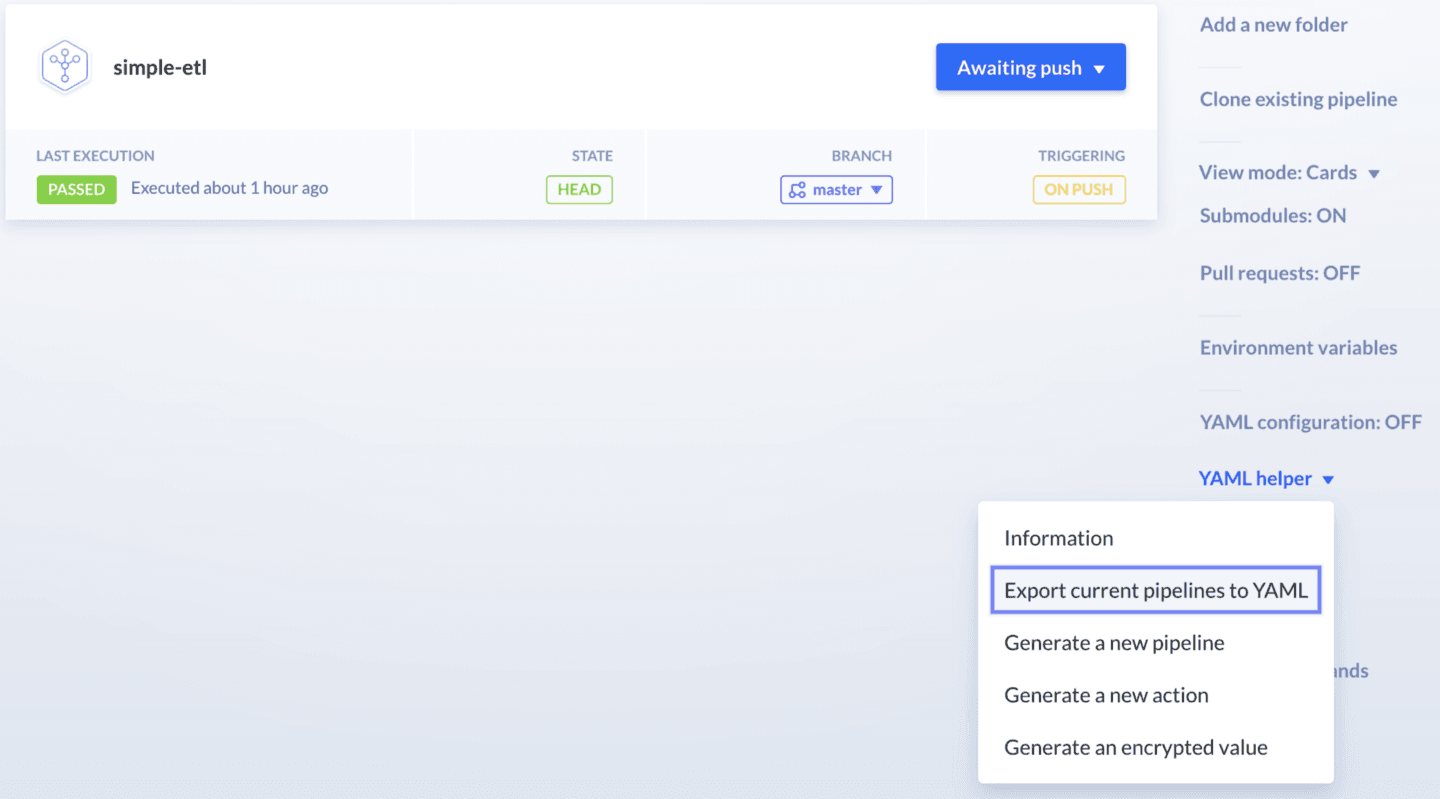
Conclusion
In this article, we looked at three ways to make you more efficient in building professional Python projects. First, you can use the tempfile package any time you need a temporary directory. This can help to ensure idempotency in handling files. Second, you can swap iterrows for itertuples if you need to iterate over a Pandas dataframe, and you don’t need access to the index. Lastly, to leverage automation and make you much more productive with any code deployment, you can use Buddy to build sophisticated CI/CD pipelines with just a few clicks in your browser.
Thank you for reading! If this article was useful, follow me to see my next posts.
References & additional resources:
1.Build Docker image — Buddy
2.CI/CD for Python applications — Buddy